Pintos Project2
学校的pintos project2实验大作业记录
GitHub:完成代码
目录
安装Pintos
References:
https://zhuanlan.zhihu.com/p/104497182
https://blog.csdn.net/geeeeeker/article/details/108104466
YouTube教程(口音迷人,但是看视频还是能看懂的)
我的环境:vmware虚拟机 Ubuntu 16.04
Install QEMU Simulator
sudo apt-get install qemu
下载pintos源码
从https://github.com/WyldeCat/pintos-anon中下载zip压缩包(Windows下载完后,往vmware直接拖进去就行),在虚拟机中解压。
Edit GDBMACROS
Open pintos/src/utils/pintos-gdb. Make the variable GDBMACROS point to pintos/src/misc/gdb-macros i.e. GDBMACROS=/home/....../pintos/src/misc/gdb-macros. Note that it should point to the full path.
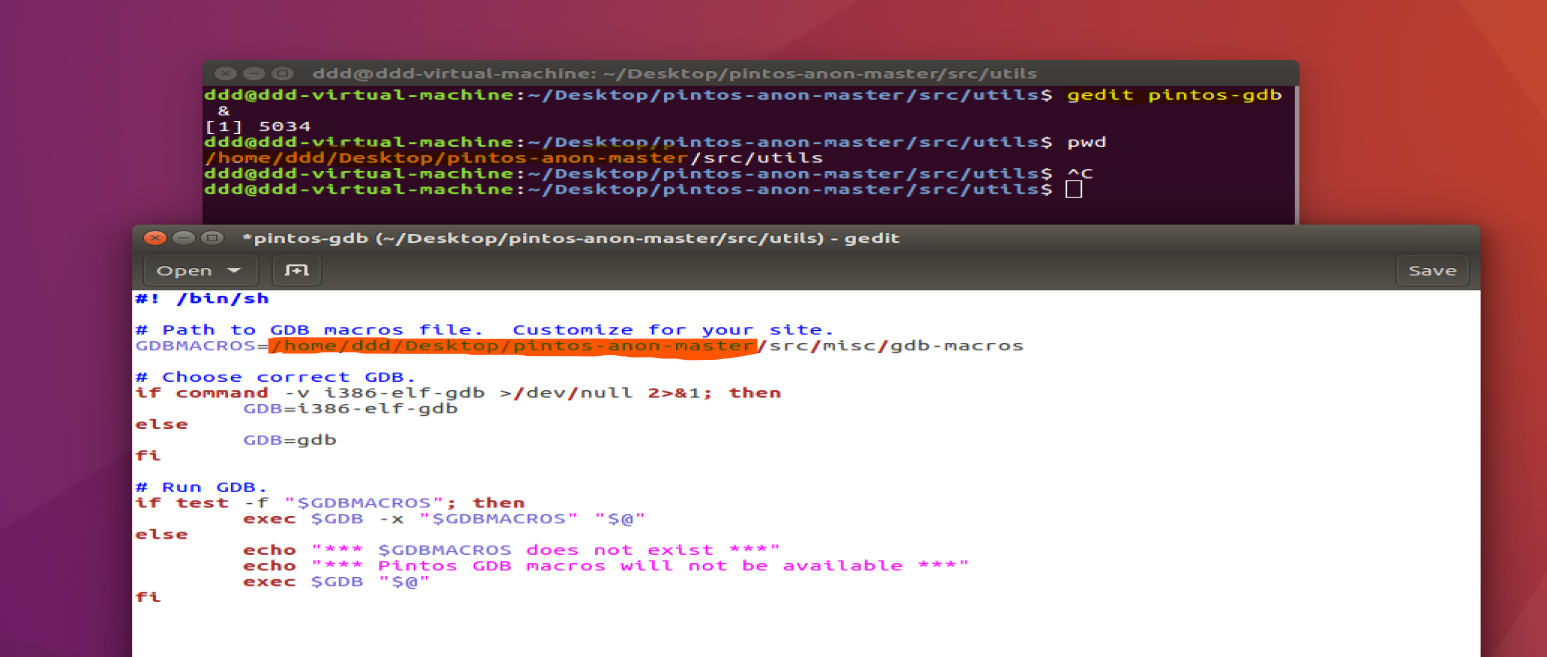
就是将如上图橙色部分将$PINTOS_DIR替换即可
编辑Makefile
编辑Makefile文件,把其中的LOADLIBES改成LDLIBS
编译utils
在xxx/pintos-anon-master/src/utils下执行make命令
编辑Make.vars文件
在src/threads/Make.vars的第七行把bochs改成qemu
编译threads
在threads文件夹下执行make命令
注意:执行完后最后一句会有make[1]: Leaving directory '/home/ddd/Desktop/pintos-anon-master/src/threads/build'(每个人都不一样,后面有用)
编辑pintos
在src/utils/pintos文件中做以下更改:
- Line 103:
bocs改成qemu - (存在bug) Line 257:
kernel.bin改成/home/.../pintos/src/threads/build/kernel.bin(即之前的路径) - Line 621:把
qemu-system-i386改成qemu-system-x86_64
编辑Pintos.pm
- (存在bug)Line 362:
loader.bin改成/home/.../pintos/src/threads/build/loader.bin(同上)
把utils路径加入PATH变量
打开~/.bashrc 最后一行加上export PATH=/home/.../pintos/src/utils:$PATH
重新加载terminals
source ~/.bashrc
运行pintos
pintos run alarm-multiple
验证配置成功
- 方法1:在utils文件夹下运行
pintos run alarm-multiple,成功时会出现
- 方法2:在threads文件夹下运行
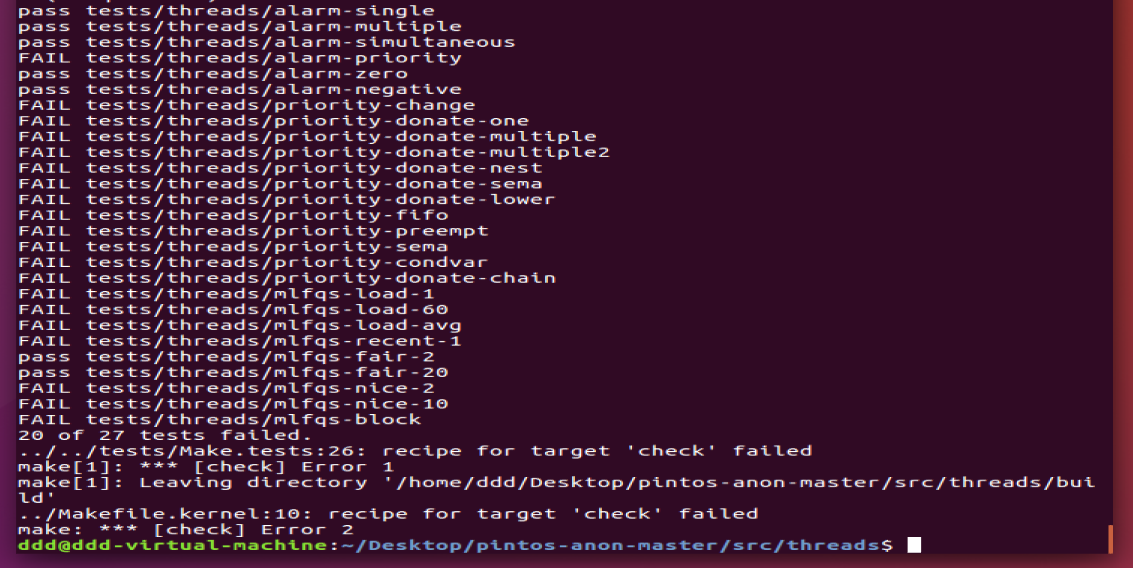
make check,执行时间比较长,最后会出现结果提示通过7个测试
文件系统
创建磁盘(不确定需不需要做,之前在debug的时候做了,一团乱麻了属于是)
the current directory is userprog/build:
pintos-mkdisk filesys.dsk --filesys-size=2
pintos -- -f -q
pintos -p ../../examples/echo -a echo -- -q
pintos -- -q run 'echo x'
bug修复
出现报错:Kernel panic in run: PANIC at ../../threads/init.c:264 in parse_options(): unknown option '-f' (use -h for help) Call stack: 0xc00285bf
把前面标了bug的部分threads改成userprog,再次在userprog, utils 文件夹下执行make
工具
由于在虚拟机中编程实在太过于阴间,我找到了vscode通过ssh连接虚拟机的方法,成功在windows中使用vscode编程。
配置方法:https://blog.csdn.net/qq_40300094/article/details/114639608
另外虚拟机ip最好设置固定或者默认时间久一些
Project2 背景
参考:
https://github.com/Wang-GY/pintos-project2/blob/master/project_report.md
http://www.cs.jhu.edu/~huang/cs318/fall18/project/project2.html
https://zhuanlan.zhihu.com/p/343328700
https://zhuanlan.zhihu.com/p/340428650
背景
到目前为止,您在 Pintos 下运行的所有代码都已成为操作系统内核的一部分。这意味着,例如,上次分配的所有测试代码都作为内核的一部分运行,可以完全访问系统的特权部分。一旦我们开始在操作系统之上运行用户程序,就不再是这样了,这个项目就处理接下来的情况。
我们允许一次运行多个进程。每个进程有一个线程(不支持多线程进程)。用户程序是在他们拥有整台机器的错觉下编写的。这意味着,当您一次加载和运行多个进程时,您必须正确管理内存、调度和其他状态,以保持这种错觉。
在之前的项目中,我们将测试代码直接编译到您的内核中,因此我们必须在内核中要求某些特定的功能接口。从现在开始,我们将通过运行用户程序来测试您的操作系统,这给了你更大的自由。您必须确保用户程序接口满足此处描述的规范,但即使考虑到该限制,您仍可以随意重构或重写内核代码。
userprog文件夹下文件的用处
- 加载 ELF 二进制文件并启动进程:process.c/h
- 一个简单的 80 x 86 硬件页表管理器。尽管您可能不想为此项目修改此代码,但您可能希望调用其中的一些函数:pagedir.c/h
- 每当用户进程想要访问某些内核功能时,它都会调用系统调用。这是一个骨架系统调用处理程序。目前,它只是打印一条消息并终止用户进程。在本项目的第 2 部分中,您将添加代码以执行系统调用所需的所有其他操作:syscall.c/h
- 当用户进程执行特权或禁止操作时,它会作为“异常”或“错误”进入内核。(3) 这些文件处理异常。目前,所有异常都只是打印一条消息并终止进程。项目 2 的一些(但不是全部)解决方案需要
page_fault()在此文件中进行修改:exception.c/h - 80 x 86 是一种分段架构。全局描述符表 (GDT) 是一个描述正在使用的段的表。这些文件设置了全局描述符表。您不需要为任何项目修改这些文件。如果您对 GDT 的工作方式感兴趣,可以阅读代码:gdt.c/h
- 任务状态段 (TSS) 用于 80 x 86 架构任务切换。Pintos 仅在用户进程进入中断处理程序时使用 TSS 来切换堆栈,Linux 也是如此。您不需要为任何项目修改这些文件。如果您对 TSS 的工作方式感兴趣,可以阅读代码:tss.c/h
简而言之,我们需要改变的文件只有:process.c/h、syscall.c/h、exception.c/h(是不是感觉好多了
API
//filesys.h
#ifndef FILESYS_FILESYS_H
#define FILESYS_FILESYS_H
#include <stdbool.h>
#include "filesys/off_t.h"
/* Sectors of system file inodes. */
#define FREE_MAP_SECTOR 0 /* Free map file inode sector. */
#define ROOT_DIR_SECTOR 1 /* Root directory file inode sector. */
/* Block device that contains the file system. */
struct block *fs_device;
void filesys_init (bool format);
void filesys_done (void);
bool filesys_create (const char *name, off_t initial_size);
struct file *filesys_open (const char *name);
bool filesys_remove (const char *name);
#endif /* filesys/filesys.h */
//file.h
#ifndef FILESYS_FILE_H
#define FILESYS_FILE_H
#include "filesys/off_t.h"
struct inode;
/* Opening and closing files. */
struct file *file_open (struct inode *);
struct file *file_reopen (struct file *);
void file_close (struct file *);
struct inode *file_get_inode (struct file *);
/* Reading and writing. */
off_t file_read (struct file *, void *, off_t);
off_t file_read_at (struct file *, void *, off_t size, off_t start);
off_t file_write (struct file *, const void *, off_t);
off_t file_write_at (struct file *, const void *, off_t size, off_t start);
/* Preventing writes. */
void file_deny_write (struct file *);
void file_allow_write (struct file *);
/* File position. */
void file_seek (struct file *, off_t);
off_t file_tell (struct file *);
off_t file_length (struct file *);
#endif /* filesys/file.h */
虚拟内存布局
Pintos 中的虚拟内存分为两个区域:用户虚拟内存和内核虚拟内存。用户虚拟内存范围从虚拟地址 0 到PHYS_BASE,在threads/vaddr.h 中定义 ,默认为0xc0000000 (3 GB)。内核虚拟内存占用剩余的虚拟地址空间, PHYS_BASE最多 4 GB。
用户虚拟内存是每个进程的。当内核从一个过程到另一个切换,它也通过改变处理器的页面目录基址寄存器(见切换用户的虚拟地址空间 userprog / pagedir.c中pagedir_activate())。 struct thread包含一个指向进程页表的指针。
内核虚拟内存是全局的。无论用户进程或内核线程正在运行什么,它总是以相同的方式映射。在 Pintos 中,内核虚拟内存一对一映射到物理内存,从PHYS_BASE. 即虚拟地址 PHYS_BASE访问物理地址 0,虚拟地址PHYS_BASE+ 0x1234访问物理地址0x1234,依此类推,直到机器物理内存的大小。
用户程序只能访问自己的用户虚拟内存。访问内核虚拟内存的尝试导致页面错误,通过在userprog / exception.c中的page_fault()处理,且过程将被终止。内核线程可以访问内核虚拟内存,如果用户进程正在运行,还可以访问正在运行的进程的用户虚拟内存。但是,即使在内核中,尝试访问未映射的用户虚拟地址的内存也会导致page fault。
建议实现顺序
-
参数传递:每个用户程序都会立即出现页面错误,直到实现参数传递之后。
现在,您可能只想改变
setup_stack()中的*esp = PHYS_BASE;至
*esp = PHYS_BASE - 12;这适用于任何不检查其参数的测试程序,尽管其名称将打印为
(null).在实现参数传递之前,您应该只运行不传递命令行参数的程序。尝试向程序传递参数将在程序名称中包含这些参数,这可能会失败。
-
用户内存访问:所有系统调用都需要读取用户内存。很少有系统调用需要写入用户内存。
-
系统调用基础结构:实现足够的代码以从用户堆栈中读取系统调用号并根据它分派给处理程序。
-
系统调用
exit。每个以正常方式完成的用户程序都会调用exit. 即使是一个从main()返回的程序,它也间接调用exit(见lib/user/entry.c中_start())。 -
系统调用
write写入 fd 1(系统控制台)。我们所有的测试程序都写到控制台(用户进程版本printf()就是这样实现的),所以write在可用之前它们都会出现故障。 -
现在,把
process_wait()改为无限循环(永远等待)。现在提供的实现会立即返回,因此 Pintos 将在任何进程实际运行之前关闭。您最终需要提供正确的实现。
实现上述后,用户进程应该最少工作。至少,他们可以写入控制台并正确退出。然后您可以优化您的实现,以便一些测试开始通过。
任务
-
处理终止信息
每当用户进程终止时,因为它调用
exit或出于任何其他原因,打印进程的名称和退出代码,格式为printf ("%s: exit(%d)\n", ...);打印的名称应该是传递给process_execute()的全名,省略命令行参数。当不是用户进程的内核线程终止或调用halt系统调用时,不要打印这些消息。当进程加载失败时,该消息是可选的。练习 2.1
当进程终止时, 打印
"%s: exit(%d)\n"格式为进程名称和退出状态的退出消息。 -
参数传递
目前,
process_execute()不支持向新进程传递参数。通过扩展process_execute()来实现此功能, 而不是简单地将程序文件名作为其参数,而是将其以空格分隔成单词。第一个词是程序名称,第二个词是第一个参数,依此类推。也就是说,process_execute("grep foo bar")应该运行grep传递两个参数foo和bar。练习 2.2
为
process_execute().添加参数传递支持。在命令行中,多个空格等价于一个空格,所以这
process_execute("grep foo bar")相当于我们原来的例子。您可以对命令行参数的长度施加合理的限制。例如,您可以将参数限制为适合单个页面 (4 kB) 的参数。(pintos实用程序可以传递给内核的命令行参数有 128 字节的无关限制。)您可以按您喜欢的任何方式解析参数字符串。如果你迷路了,看看
strtok_r(),在lib/string.h 中原型化并在lib/string.c中用完整的注释实现。您可以通过查看手册页(man strtok_r在提示符下运行)找到有关它的更多信息。 -
访问用户内存
作为系统调用的一部分,内核必须经常通过用户程序提供的指针访问内存。内核在这样做时必须非常小心,因为用户可以传递一个空指针、一个指向未映射虚拟内存的指针或一个指向内核虚拟地址空间的指针(上图PHYS_BASE)。通过终止违规进程并释放其资源,必须拒绝所有这些类型的无效指针,而不会对内核或其他正在运行的进程造成损害。
练习 2.3
支持读取和写入用户内存以进行系统调用。
至少有两种合理的方法可以正确地做到这一点。
第一种方法是验证用户提供的指针的有效性,然后取消引用它。如果您选择这条路线,您将需要查看
userprog/pagedir.c和threads/vaddr.h中的函数。这是处理用户内存访问的最简单方法。第二种方法是只检查用户指针是否指向下方
PHYS_BASE,然后取消引用它。无效的用户指针将导致“页面错误”,你可以通过修改代码的处理page_fault()在userprog / exception.c。这种技术通常更快,因为它利用了处理器的 MMU,所以它往往用于实际内核(包括 Linux)。无论哪种情况,您都需要确保不会“泄漏”资源。例如,假设您的系统调用使用
malloc(). 如果之后遇到无效的用户指针,您仍然必须确保释放锁定或释放内存页面。如果您选择在取消引用之前验证用户指针,这应该很简单。如果无效指针导致页面错误,则更难处理,因为无法从内存访问中返回错误代码。因此,对于那些想要尝试后一种技术的人,我们将提供一些有用的代码:/* 在用户虚拟地址 UADDR 读取一个字节。 UADDR 必须低于 PHYS_BASE。 如果成功则返回字节值,如果 发生段错误则返回 -1 。*/ static int get_user (const uint8_t *uaddr) { int result; asm ("movl $1f, %0; movzbl %1, %0; 1:" : "=&a" (result) : "m" (*uaddr)); return result; } /* 将 BYTE 写入用户地址 UDST。 UDST 必须低于 PHYS_BASE。 如果成功则返回真,如果发生段错误则返回假。*/ static bool put_user (uint8_t *udst, uint8_t byte) { int error_code; asm ("movl $1f, %0; movb %b2, %1; 1:" : "=&a" (error_code), "=m" (*udst) : "q" (byte)); return error_code != -1; }这些函数中的每一个都假定用户地址已经被验证为低于
PHYS_BASE。他们还假设您已经进行了修改,page_fault()以便内核中的页面错误仅设置eax为0xffffffff并将其以前的值复制到eip. -
系统调用
练习 2.4.1
在
userprog/syscall.c实现系统调用处理程序。我们提供的框架实现通过终止进程来“处理”系统调用。它将需要检索系统调用号,然后是任何系统调用参数,并执行适当的操作。练习 2.4.2
实现以下系统调用。列出的原型是包含
lib/user/syscall.h的用户程序看到的原型。(这个头文件,以及lib/user中的所有其他头文件,仅供用户程序使用。)每个系统调用的系统调用号在lib/syscall-nr.h中定义 -
拒绝写入可执行文件
练习 2.5
添加代码以拒绝写入用作可执行文件的文件。许多操作系统这样做是因为如果进程试图运行正在磁盘上更改的代码,则会产生不可预测的结果。一旦在项目 3 中实现了虚拟内存,这一点尤其重要,但即使现在也不会受到影响。
您可以使用
file_deny_write()来防止写入打开的文件。调用file_allow_write(),文件将重新启用它们(除非文件被另一个打开程序拒绝写入)。关闭文件也将重新启用写入。因此,要拒绝写入进程的可执行文件,只要进程仍在运行,您就必须保持它处于打开状态。
实现过程
orz!
本项目均为参考https://github.com/NicoleMayer/pintos_project2的代码和文档,根据实验过程一步步“推演”的结果,代码和源代码基本一致。 由于并非原作者,理解可能不尽正确,还望谅解以及指正
参数传递
strtok_r函数
需要用到strtok_r函数
char *
strtok_r (char *s, const char *delimiters, char **save_ptr) ;
函数的返回值是 排在前面的被分割出的字串,或者为NULL
s是传入的字符串。需要注意的是 :第一次使用strtok_r之后,要把str置为NULL, delim指向依据分割的字符串,常见的空格“ ” 逗号“,”等。 saveptr保存剩下待分割的字符串。
注意:strtok_r会改变s的值,所以需要复制后再进行操作
数据结构
数据结构thread(thread.h)修改(这些修改在参数传递部分非必须,暂且提一嘴,后面会有详细的讨论):
/* Structure for Task2 */
struct list childs; /* The list of childs */
struct child * thread_child; /* Store the child of this thread */
int st_exit; /* Exit status */
struct semaphore sema; /* Control the child process's logic, finish parent waiting for child */
bool success; /* Judge whehter the child's thread execute successfully */
struct thread* parent; /* Parent thread of the thread */
线程的同步操作是依靠struct thread里的success变量以及信号量sema的增减实现的。success记录了线程是否成功执行,而通过创建子进程时父进程信号量减少、子进程结束时父进程信号量增加来实现父进程等待子进程的效果,并保证子进程结束唤醒父进程。
信号量在操作系统课上有讲过, sema_up()和sema_down()类似于signal()和wait()
这些量的初始化和改变在代码里都可以找到,就不赘述了
完成函数
参数传递的任务是重写process_execute()以及相关函数,使得传入的filename分割成文件名、参数,并压入栈中
就是…我们在开始执行的时候要把它(可执行文件)从硬盘load(用load函数)到内存里,然后根据用户在命令行输入的参数初始化程序的栈(这里栈指针用esp来表示),也就是把参数按照某种方式一个个压进栈里。然后才跳转到这个程序的start处让它自己运行去。
tid_t
process_execute (const char *file_name)
{
char *fn_copy0, *fn_copy1;
tid_t tid;
/* Make a copy of FILE_NAME.
Otherwise strtok_r will modify the const char *file_name. */
fn_copy0 = palloc_get_page(0);//palloc_get_page(0)动态分配了一个内存页
if (fn_copy0 == NULL)//分配失败
return TID_ERROR;
/* Make a copy of FILE_NAME.
Otherwise there's a race between the caller and load(). */
fn_copy1 = palloc_get_page (0);
if (fn_copy1 == NULL)
{
palloc_free_page(fn_copy0);
return TID_ERROR;
}
//把file_name 复制2份,PGSIZE为页大小
strlcpy (fn_copy0, file_name, PGSIZE);
strlcpy (fn_copy1, file_name, PGSIZE);
/* Create a new thread to execute FILE_NAME. */
char *save_ptr;
char *cmd = strtok_r(fn_copy0, " ", &save_ptr);
tid = thread_create(cmd, PRI_DEFAULT, start_process, fn_copy1);
palloc_free_page(fn_copy0);
if (tid == TID_ERROR)
{
palloc_free_page (fn_copy1);
return tid;
}
//后续exec系统调用要求,懒得删了...
/* Sema down the parent process, waiting for child */
sema_down(&thread_current()->sema);
if (!thread_current()->success) return TID_ERROR;//can't create new process thread,return error
return tid;
}
thread_create()函数创建一个内核线程用来执行这个线程
/* Creates a new kernel thread named NAME with the given initial
PRIORITY, which executes FUNCTION passing AUX as the argument,
and adds it to the ready queue. Returns the thread identifier
for the new thread, or TID_ERROR if creation fails.*/
tid_t thread_create(const char *name, int priority,
thread_func *function, void *aux);
简而言之,就是把参数aux传给fuction函数,线程创建时会执行fuction函数,所以我们接下来需要完成start_process()函数:
压栈过程在函数start_process()和push_argument中完成
用户的栈在这里有过一些介绍,pintos文档中也有描述:

什么意思呢?
首先我们要知道,用户虚拟内存内存和内核虚拟内存的分界线是哪里(也就是,哪块地方是用户的,哪块是内核的)。这里的虚拟内存的地址空间是0x00000000-0xFFFFFFFF这一共4GB的内存,其中下面的3GB(0x0-0xC0000000)是用户的,上面1GB是内核的。用户自己只能在用户内存地址空间里搞事情,内核在内核空间里搞事情。那么用户的栈呢,在用户空间的最顶部,从上往下增长。(也就是说,栈上的东西应该是从高地址往低地址来的,这个叫压栈…比如一开始你在0xbffffffc放了个1字节的东西,下一个你应该放到0xbffffffb这样)。
现在再回忆上面那个图,我们发现呢 我们首先要把esp(栈指针)放在0xC0000000的地方,然后按顺序做这几件事:
(1)把命令按空格拆开,搞成一堆字符串(以\0结尾)
(2)从后往前循环,把esp往下压一个argv[i]的长度,然后把argv[i]给copy到那个地方
(3)将esp接着往下压,压到是4的倍数(这个叫word-align),只是会让速度更快,不做也没啥事。
(4)把从argv[argc+1]一直到argv[0]的地址一个个写进去(这些地址就是你刚刚压进去的那些位置)
(5)再把(4)中放argv[0]的地址的 那个地址(有点绕,多看几遍)放进去
(6)压进去一个argc
(7)压进去一个0,作为return address
static void
start_process (void *file_name_)
{
char *file_name = file_name_;
struct intr_frame if_;
bool success;
char *fn_copy=malloc(strlen(file_name)+1);
strlcpy(fn_copy,file_name,strlen(file_name)+1);
/* Initialize interrupt frame */
memset (&if_, 0, sizeof if_);
if_.gs = if_.fs = if_.es = if_.ds = if_.ss = SEL_UDSEG;
if_.cs = SEL_UCSEG;
if_.eflags = FLAG_IF | FLAG_MBS;
/*load executable. */
//此处发生改变,需要传入文件名
char *token, *save_ptr;
file_name = strtok_r (file_name, " ", &save_ptr);
success = load (file_name, &if_.eip, &if_.esp);
if (success)
{
/* Our implementation for Task 1:
Calculate the number of parameters and the specification of parameters */
int argc = 0;
/* The number of parameters can't be more than 50 in the test case */
int argv[50];
for (token = strtok_r (fn_copy, " ", &save_ptr); token != NULL; token = strtok_r (NULL, " ", &save_ptr)){
if_.esp -= (strlen(token)+1);//栈指针向下移动,留出token+'\0'的大小
memcpy (if_.esp, token, strlen(token)+1);//token+'\0'复制进去
argv[argc++] = (int) if_.esp;//存储 参数的地址
}
push_argument (&if_.esp, argc, argv);//将参数的地址压入栈
/* Record the exec_status of the parent thread's success and sema up parent's semaphore */
thread_current ()->parent->success = true;
sema_up (&thread_current ()->parent->sema);
}
/* Free file_name whether successed or failed. */
palloc_free_page (file_name);
free(fn_copy);
if (!success)
{
thread_current ()->parent->success = false;
sema_up (&thread_current ()->parent->sema);
thread_exit ();
}
/* Start the user process by simulating a return from an
interrupt, implemented by intr_exit (in
threads/intr-stubs.S). Because intr_exit takes all of its
arguments on the stack in the form of a `struct intr_frame',
we just point the stack pointer (%esp) to our stack frame
and jump to it. */
asm volatile ("movl %0, %%esp; jmp intr_exit" : : "g" (&if_) : "memory");
NOT_REACHED ();
}
/* Our implementation for Task 1:
Push argument into stack, this method is used in Task 1 Argument Pushing */
void
push_argument (void **esp, int argc, int argv[]){
*esp = (int)*esp & 0xfffffffc;
*esp -= 4;//四位对齐(word-align)下压uint8_t大小
*(int *) *esp = 0;
/*下面这个for循环的意义是:按照argc的大小,循环压入argv数组,这也符合argc和argv之间的关系*/
for (int i = argc - 1; i >= 0; i--)
{
*esp -= 4;
*(int *) *esp = argv[i];
}
*esp -= 4;
*(int *) *esp = (int) *esp + 4;//压入argv[0]的地址
*esp -= 4;
*(int *) *esp = argc;
*esp -= 4;
*(int *) *esp = 0;
}
验证一下
进入userprog/build
pintos -v -k -T 60 --qemu --filesys-size=2 -p tests/userprog/args-single -a args-single -- -q -f run 'args-single onearg'
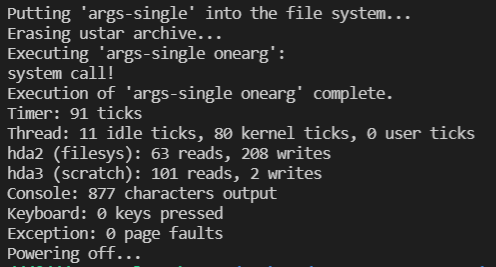
可以发现它没有成功打印出onearg,而是打出system call!
这是为啥呢?通过搜索发现
static void
syscall_handler (struct intr_frame *f UNUSED)
{
printf ("system call!\n");
thread_exit ();
}
好吧,还得继续完成syscall才能通过这些(得完成write系统调用)
处理终止信息
在thread结构体中,我们已经加入了 st_exit用来保存退出状态exit_state
我们在exception.c kill()中可以发现当出现意外结束时,存在判断
switch (f->cs)
{
case SEL_UCSEG:
/* User's code segment, so it's a user exception, as we
expected. Kill the user process. */
printf ("%s: dying due to interrupt %#04x (%s).\n",
thread_name (), f->vec_no, intr_name (f->vec_no));
intr_dump_frame (f);
thread_exit ();
case SEL_KCSEG:
/* Kernel's code segment, which indicates a kernel bug.
Kernel code shouldn't throw exceptions. (Page faults
may cause kernel exceptions--but they shouldn't arrive
here.) Panic the kernel to make the point. */
intr_dump_frame (f);
PANIC ("Kernel bug - unexpected interrupt in kernel");
default:
/* Some other code segment? Shouldn't happen. Panic the
kernel. */
printf ("Interrupt %#04x (%s) in unknown segment %04x\n",
f->vec_no, intr_name (f->vec_no), f->cs);
thread_exit ();
那我们需要做的工作就是在thread_exit()中加入打印终止信息
/*Print the information */
printf ("%s: exit(%d)\n",thread_name(), thread_current()->st_exit);
thread_name应该是脱掉参数后纯程序名
打印的名称应该是传递给
process_execute()的全名,省略命令行参数。
我们之前在参数传递部分已经完成
st_exit在后续的系统调用的时候再进行赋值操作
系统调用
终于开始最难的部分了……
pintos 要求
要实现系统调用,您需要提供在用户虚拟地址空间中读写数据的方法。在获得系统调用号之前,您需要这种能力,因为系统调用号在用户虚拟地址空间中的用户堆栈上。这可能有点棘手:如果用户提供无效指针、指向内核内存的指针或部分位于这些区域之一中的块怎么办?您应该通过终止用户进程来处理这些情况。我们建议在实现任何其他系统调用功能之前编写和测试此代码。有关详细信息,请参阅3.1.5 访问用户内存部分。
使用check_ptr2()函数检查地址和页面的有效性,来确保系统调用时各种操作的合法性。
之后的要求,我放在文件处理的系统调用部分了
整体框架
总的来说,系统调用部分的主要流程为:
syscall_init存储了系统调用的类型。当中断发生,参数(包含了系统调用的类型)入栈,这时,syscall_handler弹出栈顶元素,也就是系统调用的类型,并去syscall_init里寻找有无定义该系统调用,找到了的话就转而执行该系统调用。 系统调用部分函数调用关系流程图:

系统调用实现
系统调用是什么?
在 Pintos 中,用户程序调用整数 $0x30进行系统调用,此时用户就会把没有权限干的活交给系统调用去干,系统调用的栈指针就是esp,返回值是eax。我们需要干的事说白了就是根据esp指向栈的参数内容,完成系统调用对应的功能,最后把返回值放到eax里。
esp的布局如下:
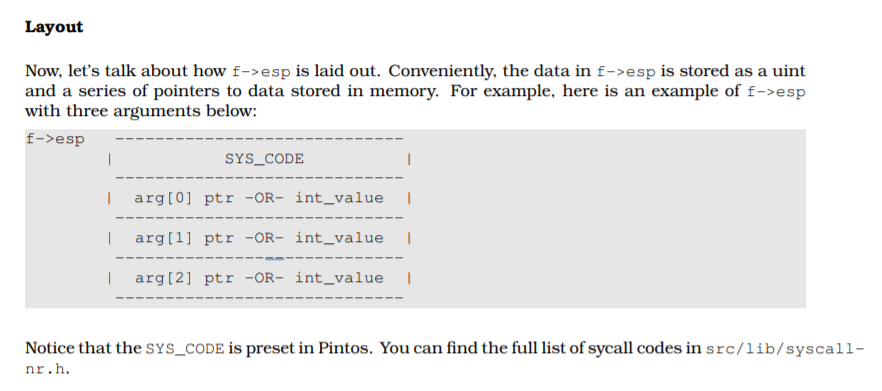
在lib\user\syscall下描述了每个系统调用传递了哪些参数,例如:
bool
create (const char *file, unsigned initial_size)
{
return syscall2 (SYS_CREATE, file, initial_size);
}
check_ptr2()
当实现系统调用时,需要访问用户的内存,这时候就要判断指针指向的地址是否合法了
实现思路见任务的访问用户内存小节,原代码应该是使用第二种方法
/* New method to check the address and pages to pass test sc-bad-boundary2, execute */
void *
check_ptr2(const void *vaddr)
{
/* Judge address */
if (!is_user_vaddr(vaddr))//是否为用户地址
{
exit_special ();
}
/* Judge the page */
void *ptr = pagedir_get_page (thread_current()->pagedir, vaddr);//是否为用户地址
if (!ptr)
{
exit_special ();
}
/* Judge the content of page */
uint8_t *check_byteptr = (uint8_t *) vaddr;
for (uint8_t i = 0; i < 4; i++)
{
if (get_user(check_byteptr + i) == -1)
{
exit_special ();
}
}
return ptr;
}
/* Method in document to handle special situation */
/* 在用户虚拟地址 UADDR 读取一个字节。
UADDR 必须低于 PHYS_BASE。
如果成功则返回字节值,如果
发生段错误则返回 -1 。*/
static int
get_user (const uint8_t *uaddr)
{
int result;
asm ("movl $1f, %0; movzbl %1, %0; 1:" : "=&a" (result) : "m" (*uaddr));
return result;
}
在page_fault()中需要管理无效的用户指针导致的page_fault
They also assume that you’ve modified
page_fault()so that a page fault in the kernel merely setseaxto0xffffffffand copies its former value intoeip.
user = (f->error_code & PF_U) != 0;
//IF USER ERROR IS FALSE THEN PUT THE RETURN ADDRESS INTO EIP AND RETURN ERROR INTO EAX
if (!user)
{
f->eip = f->eax;//eip:寄存器存放下一个CPU指令存放的内存地址 EAX:返回值。bshd
f->eax = -1;
return;
}
对于错误,需要给予exit_state=-1,并且结束线程
If a system call is passed an invalid argument, acceptable options include returning an error value (for those calls that return a value), returning an undefined value, or terminating the process.
/* Handle the special situation for thread */
void
exit_special (void)
{
thread_current()->st_exit = -1;
thread_exit ();
}
syscall_init()
初始化系统调用,通过syscall数组来存储13个系统调用,在syscall_handler里通过识别数组的序号决定调用哪一个系统调用。
在syscall-nr.h下,说明了所有的系统调用号,我节选了project2需要完成的部分:
/* Projects 2 and later. */
SYS_HALT, /* Halt the operating system. */
SYS_EXIT, /* Terminate this process. */
SYS_EXEC, /* Start another process. */
SYS_WAIT, /* Wait for a child process to die. */
SYS_CREATE, /* Create a file. */
SYS_REMOVE, /* Delete a file. */
SYS_OPEN, /* Open a file. */
SYS_FILESIZE, /* Obtain a file's size. */
SYS_READ, /* Read from a file. */
SYS_WRITE, /* Write to a file. */
SYS_SEEK, /* Change position in a file. */
SYS_TELL, /* Report current position in a file. */
SYS_CLOSE, /* Close a file. */
可以定义函数指针数组,在syscall_init中初始化对应的函数地址,做到当0x30中断发生的时候,根据系统调用号在后续syscall_handler里自动选择应该使用的系统调用函数
static void (*syscalls[max_syscall])(struct intr_frame *);
/* Our implementation for Task2: syscall halt,exec,wait and practice */
void sys_halt(struct intr_frame* f); /* syscall halt. */
void sys_exit(struct intr_frame* f); /* syscall exit. */
void sys_exec(struct intr_frame* f); /* syscall exec. */
/* Our implementation for Task3: syscall create, remove, open, filesize, read, write, seek, tell, and close */
void sys_create(struct intr_frame* f); /* syscall create */
void sys_remove(struct intr_frame* f); /* syscall remove */
void sys_open(struct intr_frame* f);/* syscall open */
void sys_wait(struct intr_frame* f); /*syscall wait */
void sys_filesize(struct intr_frame* f);/* syscall filesize */
void sys_read(struct intr_frame* f); /* syscall read */
void sys_write(struct intr_frame* f); /* syscall write */
void sys_seek(struct intr_frame* f); /* syscall seek */
void sys_tell(struct intr_frame* f); /* syscall tell */
void sys_close(struct intr_frame* f); /* syscall close */
syscall_init (void)
{
intr_register_int (0x30, 3, INTR_ON, syscall_handler, "syscall");
/* Our implementation for Task2: initialize halt,exit,exec */
syscalls[SYS_EXEC] = &sys_exec;
syscalls[SYS_HALT] = &sys_halt;
syscalls[SYS_EXIT] = &sys_exit;
// /* Our implementation for Task3: initialize create, remove, open, filesize, read, write, seek, tell, and close */
syscalls[SYS_WAIT] = &sys_wait;
syscalls[SYS_CREATE] = &sys_create;
syscalls[SYS_REMOVE] = &sys_remove;
syscalls[SYS_OPEN] = &sys_open;
syscalls[SYS_WRITE] = &sys_write;
syscalls[SYS_SEEK] = &sys_seek;
syscalls[SYS_TELL] = &sys_tell;
syscalls[SYS_CLOSE] =&sys_close;
syscalls[SYS_READ] = &sys_read;
syscalls[SYS_FILESIZE] = &sys_filesize;
}
syscall_handler()
系统调用被调用时,中断就会自动使用这个函数进行处理
/* Smplify the code to maintain the code more efficiently */
static void
syscall_handler (struct intr_frame *f UNUSED)
{
/* For Task2 practice, just add 1 to its first argument, and print its result */
int * p = f->esp;
check_ptr2 (p + 1);//检验第一个参数
int type = * (int *)f->esp;//检验系统调用号sys_code是否合法
if(type <= 0 || type >= max_syscall){
exit_special ();
}
syscalls[type](f);//无误则执行对应系统调用函数
}
关于进程的系统调用
需要增加的数据结构在参数传递里已经完成…
halt
System Call: void halt (void)
Terminates Pintos by calling
shutdown_power_off()(declared indevices/shutdown.h). This should be seldom used, because you lose some information about possible deadlock situations, etc.
没啥好说的,直接调用shutdown_power_off()就完事
exit
System Call: void exit (int status)
Terminates the current user program, returning status to the kernel. If the process’s parent
waits for it (see below), this is the status that will be returned. Conventionally, a status of 0 indicates success and nonzero values indicate errors.
void
sys_exit (struct intr_frame* f)
{
uint32_t *user_ptr = f->esp;
check_ptr2 (user_ptr + 1);//检验第一个参数
*user_ptr++;//指针指向第一个参数
/* record the exit status of the process */
thread_current()->st_exit = *user_ptr;//保存exit_code
thread_exit ();
}
exec
System Call: pid_t exec (const char *cmd_line)
Runs the executable whose name is given in cmd_line, passing any given arguments, and returns the new process’s program id (pid). Must return pid -1, which otherwise should not be a valid pid, if the program cannot load or run for any reason. Thus, the parent process cannot return from the
execuntil it knows whether the child process successfully loaded its executable. You must use appropriate synchronization to ensure this.
args: const char *file
/* Do sytem exec */
void
sys_exec (struct intr_frame* f)
{
uint32_t *user_ptr = f->esp;
check_ptr2 (user_ptr + 1);//检查第一个参数的地址
check_ptr2 (*(user_ptr + 1));//检查第一个参数的值,即const char *file指向的地址
*user_ptr++;
f->eax = process_execute((char*)* user_ptr);//使用process_execute完成pid的返回
}
return pid -1工作在check_ptr2()函数中完成,父进程和子进程的同步操作通过sema信号量完成(在参数传递部分)
wait
System Call: int wait (pid_t pid)
Waits for a child process pid and retrieves the child’s exit status.
If pid is still alive, waits until it terminates. Then, returns the status that pid passed to
exit. If pid did not callexit(), but was terminated by the kernel (e.g. killed due to an exception),wait(pid)must return -1. It is perfectly legal for a parent process to wait for child processes that have already terminated by the time the parent callswait, but the kernel must still allow the parent to retrieve its child’s exit status, or learn that the child was terminated by the kernel.
waitmust fail and return -1 immediately if any of the following conditions is true:
pid does not refer to a direct child of the calling process.pid is a direct child of the calling process if and only if the calling process received .pid as a return value from a successful call to
execNote that children are not inherited: if A spawns child B and B spawns child process C, then A cannot wait for C, even if B is dead. A call to
wait(C)by process A must fail. Similarly, orphaned processes are not assigned to a new parent if their parent process exits before they do.The process that calls
waithas already calledwaiton pid. That is, a process may wait for any given child at most once.Processes may spawn any number of children, wait for them in any order, and may even exit without having waited for some or all of their children. Your design should consider all the ways in which waits can occur. All of a process’s resources, including its
struct thread, must be freed whether its parent ever waits for it or not, and regardless of whether the child exits before or after its parent.You must ensure that Pintos does not terminate until the initial process exits. The supplied Pintos code tries to do this by calling
process_wait()(inuserprog/process.c) frommain()(inthreads/init.c). We suggest that you implementprocess_wait()according to the comment at the top of the function and then implement thewaitsystem call in terms ofprocess_wait().Implementing this system call requires considerably more work than any of the rest.
最后一句话提示我们这是工作最多的系统调用。
好吧,根据提示我们先去根据process_wait()上方的comment去完成它叭
注释说啥呢:
Waits for thread TID to die and returns its exit status. If
it was terminated by the kernel (i.e. killed due to an
exception), returns -1. If TID is invalid or if it was not a
child of the calling process, or if process_wait() has already
been successfully called for the given TID, returns -1
immediately, without waiting.
This function will be implemented in problem 2-2. For now, it
does nothing.
- 内核终止时
- 子线程的tid不存在或其不是调用进程的子线程
- process_wait()被成功调用了,即子进程成功运行结束
以上三种情况立即返回-1
否则的话,等待线程结束返回退出状态(exit status)
process_wait()这些判断需要对应的数据结构来支持,再复习一下我们之前加入的数据结构:
/* Our implementation for struct thread to store useful information */
/* Structure for Task2 */
struct list childs; /* The list of childs 创建的所有子线程*/
struct child * thread_child; /* Store the child of this thread 存储线程的子进程,新建线程时用来存自己*/
int st_exit; /* Exit status */
struct semaphore sema; /* Control the child process's logic, finish parent waiting for child */
bool success; /* Judge whehter the child's thread execute successfully */
struct thread* parent; /* Parent thread of the thread 当前进程的父进程*/
struct child
{
tid_t tid; /* tid of the thread */
bool isrun; /* whether the child's thread is run successfully */
struct list_elem child_elem; /* list of children */
struct semaphore sema; /* semaphore to control waiting */
int store_exit; /* the exit status of child thread */
//可以看到,thread_child初始为自己的tid
//所以可以用thread_child的store_exit和sema存储 parent thread中st_exit、sema,再用child_elem变相存储在child列表里
};
当前线程创建新进程的时候,对thread_child进行处理
/* Initialize thread. */
init_thread (t, name, priority);
tid = t->tid = allocate_tid ();
/* Our implementation */
/* Initialize for the thread's child */
t->thread_child = malloc(sizeof(struct child));
t->thread_child->tid = tid;//新线程的thread_child tid初始为新线程的tid
sema_init (&t->thread_child->sema, 0);//新线程的thread_child sema初始化
list_push_back (&thread_current()->childs, &t->thread_child->child_elem);
//相当于把新线程放进子线程列表中
/* Initialize the exit status by the MAX
Fix Bug */
t->thread_child->store_exit = UINT32_MAX;
t->thread_child->isrun = false;
其中初始化线程函数init_thread中新增对这些参数的初始化:
//syscall
if (t==initial_thread) t->parent=NULL;
/* Record the parent's thread */
else t->parent = thread_current ();
/* List initialization for lists */
list_init (&t->childs);
/* Semaphore initialization for lists */
sema_init (&t->sema, 0);
t->success = true;
/* Initialize exit status to MAX */
t->st_exit = UINT32_MAX;
有了这些数据结构,差不多就行了:
int
process_wait (tid_t child_tid UNUSED)
{
/* Find the child's ID that the current thread waits for and sema down the child's semaphore */
struct list *l = &thread_current()->childs;
struct list_elem *child_elem_ptr;
child_elem_ptr = list_begin (l);
struct child *child_ptr = NULL;
while (child_elem_ptr != list_end (l))//遍历当前线程的所有子线程
{
/* list_entry:Converts pointer to list element LIST_ELEM into a pointer to
the structure that LIST_ELEM is embedded inside. Supply the
name of the outer structure STRUCT and the member name MEMBER
of the list element. */
child_ptr = list_entry (child_elem_ptr, struct child, child_elem);//把child_elem的指针变成child的指针
if (child_ptr->tid == child_tid)//找到child_tid
{
if (!child_ptr->isrun)//检查子线程之前是否已经等待过
{
child_ptr->isrun = true;
sema_down (&child_ptr->sema);//线程阻塞,等待子进程结束
break;
}
else //等待过了,has already been successfully called for the given TID
{
return -1;
}
}
child_elem_ptr = list_next (child_elem_ptr);
}
if (child_elem_ptr == list_end (l)) {//找不到child_tid
return -1;
}
//执行到这里说明子进程正常退出
list_remove (child_elem_ptr);//从子进程列表中删除该子进程,因为它已经没有在运行了,也就是说父进程重新抢占回了资源
return child_ptr->store_exit;//返回子线程exit值
}
有sema_down,自然得有sema_up,在子线程退出的时候sema_up就行
在thread_exit()中加入
/*Sema up the semaphore for the process*/
//保存下来st_exit在process_wait中使用
thread_current ()->thread_child->store_exit = thread_current()->st_exit;
//子线程退出,把资源还给父线程
sema_up (&thread_current()->thread_child->sema);
最后我们在wait里调用process_wait()即可
/* Do sytem wait */
void
sys_wait (struct intr_frame* f)
{
uint32_t *user_ptr = f->esp;
check_ptr2 (user_ptr + 1);
*user_ptr++;
f->eax = process_wait(*user_ptr);
}
关于文件的系统调用
您必须同步系统调用,以便任意数量的用户进程可以同时调用它们。特别是,从多个线程同时调用
filesys目录中提供的文件系统代码是不安全的 。您的系统调用实现必须将文件系统代码视为关键部分。不要忘记process_execute()也会访问文件。目前,我们建议不要修改filesys目录中的代码。
具体的操作是先获得文件的锁,这是为了保证用户程序在运行时,可执行文件不可被修改。然后执行完系统调用后再释放锁。这样就实现了同步操作。
数据结构
在thread结构体中加入:
/* Structure for Task3 */
struct list files; /* List of opened files 维护打开的所有文件*/
int max_file_fd; /*store max fd */
用来管理线程打开的文件,实现同步操作
其中files列表里存储的是:
/* File that the thread open */
struct thread_file
{
int fd;//file descriptor
struct file* file;
struct list_elem file_elem;//files list elem
};
什么是file descriptor呢?
百度:
文件描述符在形式上是一个非负整数。实际上,它是一个索引值,指向内核为每一个进程所维护的该进程打开文件的记录表。当程序打开一个现有文件或者创建一个新文件时,内核向进程返回一个文件描述符。在程序设计中,一些涉及底层的程序编写往往会围绕着文件描述符展开。但是文件描述符这一概念往往只适用于UNIX、Linux这样的操作系统。
习惯上,标准输入(standard input)的文件描述符是 0,标准输出(standard output)是 1,标准错误(standard error)是 2。尽管这种习惯并非Unix内核的特性,但是因为一些 shell 和很多应用程序都使用这种习惯,因此,如果内核不遵循这种习惯的话,很多应用程序将不能使用。
为了进行文件操作,我们需要建立一个锁的机制,在进行文件读写的时候,只允许一个线程进行操作。
/*Use a lock to lock process when do file operation*/
static struct lock lock_f;
void
acquire_lock_f ()
{
lock_acquire(&lock_f);
}
void
release_lock_f ()
{
lock_release(&lock_f);
}
lock_f和 files的初始化分别在thread_init()和init_thread()中完成,前者只会初始一次,而后者在创建线程的时候都会调用一次。
在线程退出的时候,得把当前线程拥有的所有文件都释放了:
//thread.c void thread_exit (void)
/*Close all the files*/
/*Our implementation for fixing the BUG that the file didn't close, PASS test file*/
struct list_elem *e;
struct list *files = &thread_current()->files;
while(!list_empty (files))
{
e = list_pop_front (files);
struct thread_file *f = list_entry (e, struct thread_file, file_elem);
acquire_lock_f ();
file_close (f->file);
release_lock_f ();
/*Remove the file in the list*/
list_remove (e);
/*Free the resource the file obtain*/
free (f);
}
write
还记得当初的参数传递的测试吗
因为没有完成系统调用write,所以无法把数据打印到控制台fd 1,也就没有办法进行测试,现在我们终于来到这一步了!
System Call: int write (int fd, const void *buffer, unsigned size)
Writes size bytes from buffer to the open file fd. Returns the number of bytes actually written, which may be less than size if some bytes could not be written.
Writing past end-of-file would normally extend the file, but file growth is not implemented by the basic file system. The expected behavior is to write as many bytes as possible up to end-of-file and return the actual number written, or 0 if no bytes could be written at all.
Fd 1 writes to the console. Your code to write to the console should write all of buffer in one call to
putbuf(), at least as long as size is not bigger than a few hundred bytes. (It is reasonable to break up larger buffers.) Otherwise, lines of text output by different processes may end up interleaved on the console, confusing both human readers and our grading scripts.
代码如下:
/* Do system write, Do writing in stdout and write in files */
void
sys_write (struct intr_frame* f)
{
uint32_t *user_ptr = f->esp;
check_ptr2 (user_ptr + 7);//for tests maybe?
check_ptr2 (*(user_ptr + 6));
*user_ptr++;
int fd = *user_ptr;
const char * buffer = (const char *)*(user_ptr+1);
off_t size = *(user_ptr+2);
if (fd == 1) {//writes to the console
/* Use putbuf to do testing */
putbuf(buffer,size);
f->eax = size;//return number written
}
else
{
/* Write to Files */
struct thread_file * thread_file_temp = find_file_id (*user_ptr);
if (thread_file_temp)
{
acquire_lock_f ();//file operating needs lock
f->eax = file_write (thread_file_temp->file, buffer, size);
release_lock_f ();
}
else
{
f->eax = 0;//can't write,return 0
}
}
}
/* Find file by the file's ID */
struct thread_file *
find_file_id (int file_id)
{
struct list_elem *e;
struct thread_file * thread_file_temp = NULL;
struct list *files = &thread_current ()->files;
for (e = list_begin (files); e != list_end (files); e = list_next (e)){
thread_file_temp = list_entry (e, struct thread_file, file_elem);
if (file_id == thread_file_temp->fd)
return thread_file_temp;
}
return false;
}
再次测试
完成系统调用write以后,终于到了激动人心的test环节:
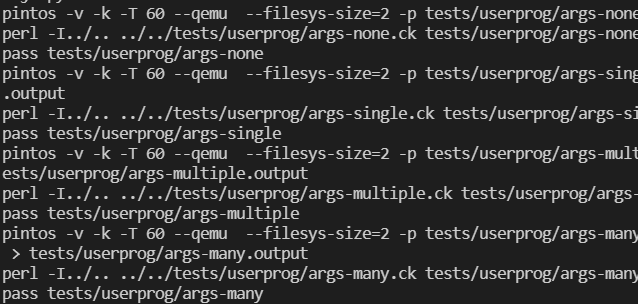
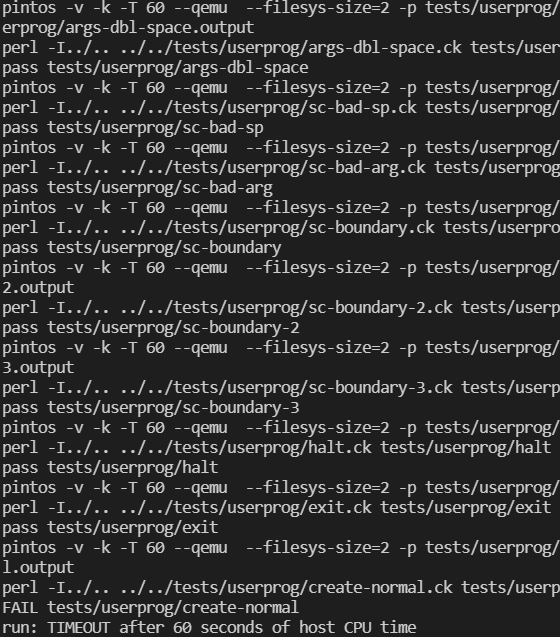
可以看到所有关于参数传递的测试都已经通过,后面的系统调用由于还未完成,所以直接timeout了
继续完成更多的系统调用吧(多数调用API)!
create
System Call: bool create (const char *file, unsigned initial_size)
Creates a new file called file initially initial_size bytes in size. Returns true if successful, false otherwise. Creating a new file does not open it: opening the new file is a separate operation which would require a
opensystem call.
创建一个新的文件,成功就返回true,失败就返回false
相对来说还是简单的,直接调用filesys_create 函数即可
/* Do sytem create, we need to acquire lock for file operation in the following methods when do file operation */
void
sys_create(struct intr_frame* f)
{
uint32_t *user_ptr = f->esp;
check_ptr2 (user_ptr + 5);//for tests maybe?
check_ptr2 (*(user_ptr + 4));
*user_ptr++;
acquire_lock_f ();
f->eax = filesys_create ((const char *)*user_ptr, *(user_ptr+1));
release_lock_f ();
}
remove
System Call: bool remove (const char *file)
Deletes the file called file. Returns true if successful, false otherwise. A file may be removed regardless of whether it is open or closed, and removing an open file does not close it. See [Removing an Open File](http://www.cs.jhu.edu/~huang/cs318/fall18/project/project2.html#Removing an Open File), for details.
删除文件,调用filesys_remove()函数即可
/* Do system remove, by calling the method filesys_remove */
void
sys_remove(struct intr_frame* f)
{
uint32_t *user_ptr = f->esp;
check_ptr2 (user_ptr + 1);//arg address
check_ptr2 (*(user_ptr + 1));//file address
*user_ptr++;
acquire_lock_f ();
f->eax = filesys_remove ((const char *)*user_ptr);
release_lock_f ();
}
open
System Call: int open (const char *file)
Opens the file called file. Returns a nonnegative integer handle called a “file descriptor” (fd), or -1 if the file could not be opened.
File descriptors numbered 0 and 1 are reserved for the console: fd 0 (
STDIN_FILENO) is standard input, fd 1 (STDOUT_FILENO) is standard output. Theopensystem call will never return either of these file descriptors, which are valid as system call arguments only as explicitly described below.Each process has an independent set of file descriptors. File descriptors are not inherited by child processes.
When a single file is opened more than once, whether by a single process or different processes, each
openreturns a new file descriptor. Different file descriptors for a single file are closed independently in separate calls tocloseand they do not share a file position.
当打开文件时返回一个不同的fd值,每个进程都有自己独立的fd集合,即使是同一个文件的不同打开也是不同的fd
我们之前创建的max_file_fd就是为了完成这个任务
/* Do system open, open file by the function filesys_open */
void
sys_open (struct intr_frame* f)
{
uint32_t *user_ptr = f->esp;
check_ptr2 (user_ptr + 1);
check_ptr2 (*(user_ptr + 1));
*user_ptr++;
acquire_lock_f ();
struct file * file_opened = filesys_open((const char *)*user_ptr);
release_lock_f ();
struct thread * t = thread_current();
if (file_opened)
{
struct thread_file *thread_file_temp = malloc(sizeof(struct thread_file));
thread_file_temp->fd = t->max_file_fd++;
thread_file_temp->file = file_opened;
list_push_back (&t->files, &thread_file_temp->file_elem);//维护files列表
f->eax = thread_file_temp->fd;
}
else// the file could not be opened
{
f->eax = -1;
}
}
filesize
System Call: int filesize (int fd)
Returns the size, in bytes, of the file open as fd.
不多说了,上代码
/* Do system filesize, by calling the function file_length() in filesystem */
void
sys_filesize (struct intr_frame* f){
uint32_t *user_ptr = f->esp;
check_ptr2 (user_ptr + 1);
*user_ptr++;//fd
struct thread_file * thread_file_temp = find_file_id (*user_ptr);
if (thread_file_temp)
{
acquire_lock_f ();
f->eax = file_length (thread_file_temp->file);//return the size in bytes
release_lock_f ();
}
else
{
f->eax = -1;
}
}
read
System Call: int read (int fd, void *buffer, unsigned size)
Reads size bytes from the file open as fd into buffer. Returns the number of bytes actually read (0 at end of file), or -1 if the file could not be read (due to a condition other than end of file). Fd 0 reads from the keyboard using
input_getc().
快速读题:读size大小的文件fd到buffer中,返回真正读到的大小(读完是0),不能读到是-1。fd0是stdin,用input_getc()
/* Check is the user pointer is valid */
bool
is_valid_pointer (void* esp,uint8_t argc){
for (uint8_t i = 0; i < argc; ++i)
{
if((!is_user_vaddr (esp)) ||
(pagedir_get_page (thread_current()->pagedir, esp)==NULL)){
return false;
}
}
return true;
}
/* Do system read, by calling the function file_tell() in filesystem */
void
sys_read (struct intr_frame* f)
{
uint32_t *user_ptr = f->esp;
/* PASS the test bad read */
*user_ptr++;
/* We don't konw how to fix the bug, just check the pointer */
int fd = *user_ptr;
uint8_t * buffer = (uint8_t*)*(user_ptr+1);
off_t size = *(user_ptr+2);
if (!is_valid_pointer (buffer, 1) || !is_valid_pointer (buffer + size,1)){
exit_special ();
}
/* get the files buffer */
if (fd == 0) //stdin
{
for (int i = 0; i < size; i++)
buffer[i] = input_getc();
f->eax = size;
}
else
{
struct thread_file * thread_file_temp = find_file_id (*user_ptr);
if (thread_file_temp)
{
acquire_lock_f ();
f->eax = file_read (thread_file_temp->file, buffer, size);
release_lock_f ();
}
else//can't read
{
f->eax = -1;
}
}
}
seek
System Call: void seek (int fd, unsigned position)
Changes the next byte to be read or written in open file fd to position, expressed in bytes from the beginning of the file. (Thus, a position of 0 is the file’s start.)
A seek past the current end of a file is not an error. A later read obtains 0 bytes, indicating end of file. A later write extends the file, filling any unwritten gap with zeros. (However, in Pintos files have a fixed length until project 4 is complete, so writes past end of file will return an error.) These semantics are implemented in the file system and do not require any special effort in system call implementation.
将文件fd中要读或写的下一个字节更改为position
/* Do system seek, by calling the function file_seek() in filesystem */
void
sys_seek(struct intr_frame* f)
{
uint32_t *user_ptr = f->esp;
check_ptr2 (user_ptr + 5);
*user_ptr++;//fd
struct thread_file *file_temp = find_file_id (*user_ptr);
if (file_temp)
{
acquire_lock_f ();
file_seek (file_temp->file, *(user_ptr+1));
release_lock_f ();
}
}
tell
System Call: unsigned tell (int fd)
Returns the position of the next byte to be read or written in open file fd, expressed in bytes from the beginning of the file.
返回下一个读写的字节在文件中的位置
/* Do system tell, by calling the function file_tell() in filesystem */
void
sys_tell (struct intr_frame* f)
{
uint32_t *user_ptr = f->esp;
check_ptr2 (user_ptr + 1);
*user_ptr++;
struct thread_file *thread_file_temp = find_file_id (*user_ptr);
if (thread_file_temp)
{
acquire_lock_f ();
f->eax = file_tell (thread_file_temp->file);
release_lock_f ();
}else{
f->eax = -1;
}
}
close
System Call: void close (int fd)
Closes file descriptor fd. Exiting or terminating a process implicitly closes all its open file descriptors, as if by calling this function for each one.
关闭文件,调用file_close,再把其从file列表里删除
/* Do system close, by calling the function file_close() in filesystem */
void
sys_close (struct intr_frame* f)
{
uint32_t *user_ptr = f->esp;
check_ptr2 (user_ptr + 1);
*user_ptr++;
struct thread_file * opened_file = find_file_id (*user_ptr);
if (opened_file)
{
acquire_lock_f ();
file_close (opened_file->file);
release_lock_f ();
/* Remove the opened file from the list */
list_remove (&opened_file->file_elem);
/* Free opened files */
free (opened_file);
}
}
额外注意
到这里我们的任务已经完成了,但是当我们测试的时候发现有3个测试fail了
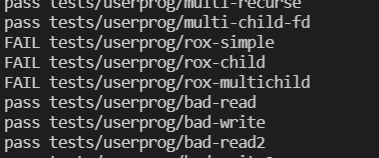
结果检查发现是这句话提醒了
我们不要忘记
process_execute()也会访问文件
只要进程仍在运行,就必须保持exec对应的文件处于打开状态
在load过程中,给文件操作加锁,同时把exec()中的文件加入到file队列里(别忘了删除file_close),在thread_exit中自动删除
结果
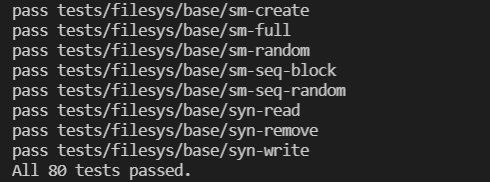
所有测试通过
关于运行自己的程序
坦诚来讲,我是猜出这个办法的,我相信一定有比我优雅合理的多的方法,所以该方法仅作为参考。
遍览目录,测试程序放在src/tests/userprog下,所以理应将咱们的程序放在该文件夹下,例如在该文件夹下新建一个文件myargs.c
在tests/userprog/Make.tests下对应位置插入以下两条代码:
25行左右加入tests/userprog/myargs_SRC = tests/userprog/myargs.c
6行tests/userprog_TESTS = $(addprefix tests/userprog/,后面,加入myargs,空格分隔
之后在src/userprog下运行make:

在userprog/build/tests/userprog下我们可以看见已经出现3个文件myargs、myargs.d、myargs.o
在src/userprog/build下运行如下代码就可以运行自己的程序了
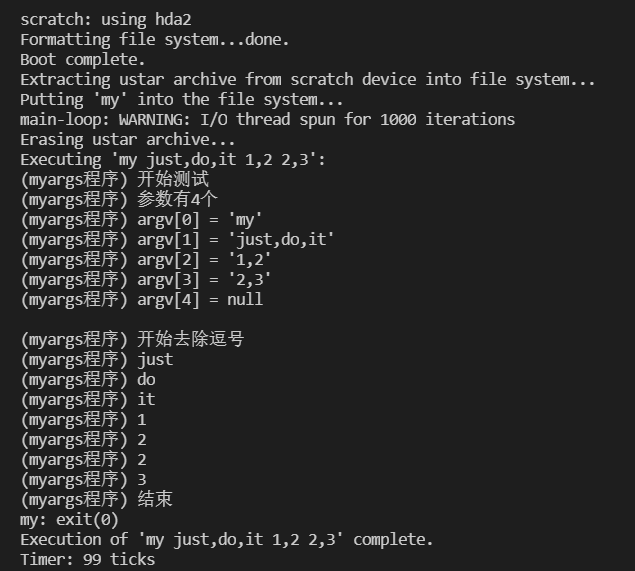
pintos -p ./tests/userprog/xxx -a yyy -- -q -f run 'yyy arg1 arg2 arg3'
例如:
pintos -p ./tests/userprog/myargs -a my -- -q -f run 'my just,do,it 1,2 2,3'